
Rebuilding a brownfield application module-by-module with AI
A 20-year-old legacy backend, a SQL Server database, a rewrite in flight, a React UI mid-migration, and a methodology that turns the strangler-pattern rewrite into an accelerant, not an anchor.

A brownfield system is software that already exists and already runs: years of accumulated code, real customers depending on it, constraints you inherited rather than chose. It’s the opposite of greenfield, the blank repo and clean prompt that most AI coding demos are built on. Those demos look impressive on Twitter and tell you almost nothing about whether AI can ship on the codebases that actually run the world.
They look more like this: a legacy backend, and a team that knows AI could help but isn’t sure where to start without breaking production.
I’m in the middle of rebuilding one of those codebases right now. Module by module. With humans in the loop at the right gates, not all of them. This isn’t a retrospective: it’s the system I’m running on today, refined over several months of daily use.
One data point to anchor what this methodology does: UX and UI work that used to take us four to six weeks now takes a single 1-2 hour session: one developer, one domain expert or PM, and a clickable prototype at the end of it. The rest of this post is the strategic case for why that’s possible and when you’d want to do it.
Why module-by-module, and not a from-scratch rewrite
The fantasy version of a legacy rewrite is this: take the team offline for six months, build a clean new application, ship it, sunset the old one. Most engineering leaders have considered it. Most have rejected it, and so did we. Here’s why:
We don’t have the luxury of going dark for six months. The business runs on this software. Customers depend on it for their daily operations. Even if we tried, the requirements would shift underneath us before we shipped, and we’d ship a system already six months out of date.
Big-bang migrations are a customer punishment. Every customer hits the same wall on the same day: workflows change, integrations break, muscle memory resets. The customers who didn’t ask for a rewrite (almost all of them) experience it as a regression, and your team spends the next six months firefighting churn instead of building.
The cutover concentrates the risk into one day. Everything either works or it doesn’t the moment you flip traffic from old to new. Module-by-module spreads that risk across dozens of small cutovers, each independently rollback-able. You trade one terrifying day for many boring weeks.
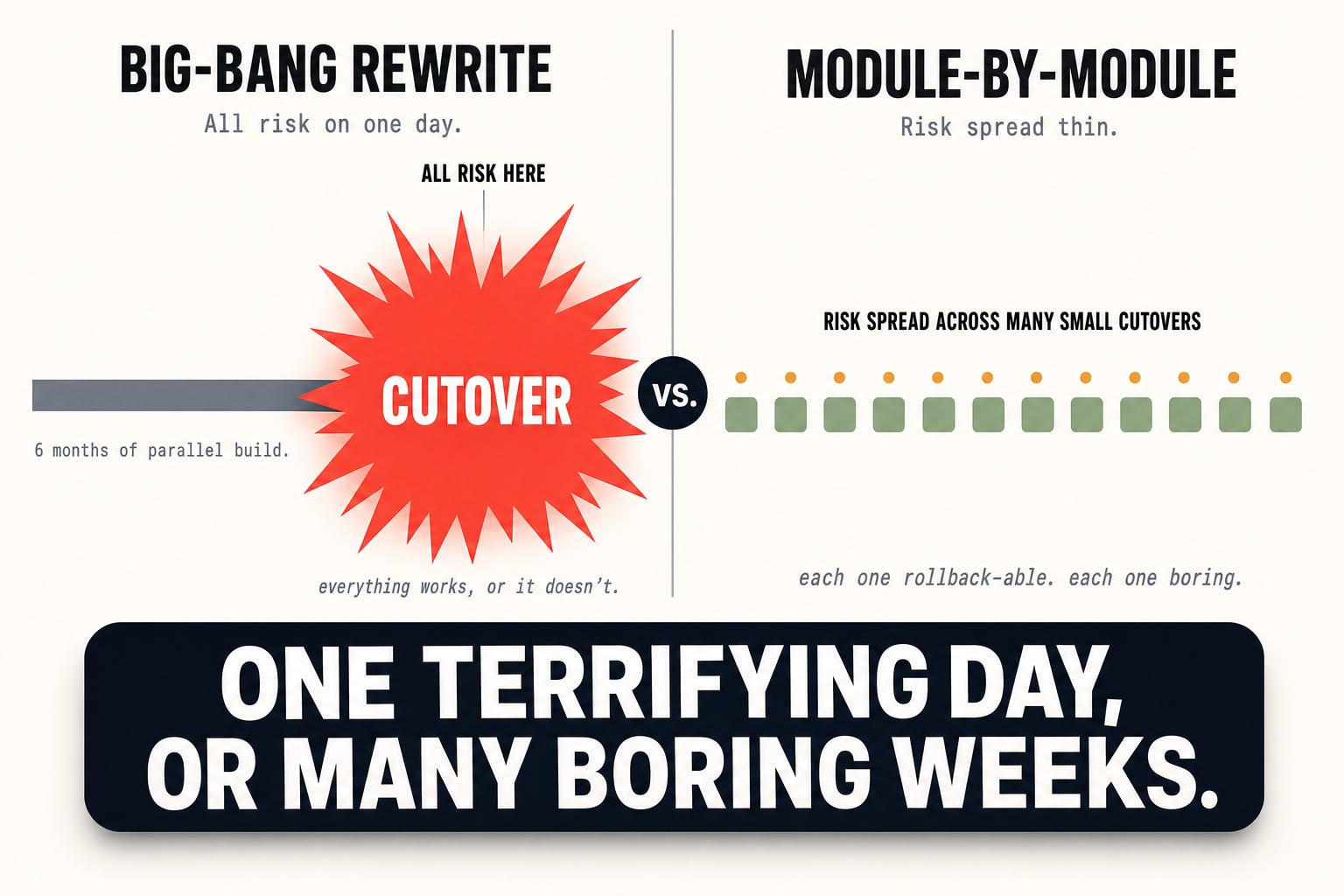
The alternative, the one we’re actually doing, is the strangler pattern. Named after the strangler fig, which grows around its host tree and replaces it from the outside in until the host can be retired and the fig is load-bearing on its own.
In practice that means:
All new development happens on the new backend. No new endpoints get added to the legacy backend, ever. The legacy backend stops growing the day you commit to this.
Any time we touch a legacy endpoint for a change, we strongly consider porting it. Not every touch is a port. But “is it cheap to port this now?” is a question we ask every time, and the answer is yes more often than the team expects.
Customers don’t experience the migration. From their perspective, features keep shipping. The UI gets better. Performance improves on the modules we’ve rebuilt. They never hit a “welcome to the new app” wall. Their muscle memory survives.
And critically: we’re not doing parity. Each module that gets rebuilt is also an opportunity to improve. Features customers have been asking about for years, features the legacy stack couldn’t accommodate, finally become possible because the module is being touched anyway. The strangler pattern isn’t lift-and-shift. It’s rebuild-while-advancing.
This is where AI changes the math. The strangler pattern stops being the expensive option and becomes the only sane one for complex brownfield applications.
The methodology in one screen
Every feature, from a one-day fix to a multi-week module rebuild, moves through the same phases. The shape is two tiers. A handful of steps run once per module to set direction, then a tight loop runs once per feature until the module is done. Not all features need every step, but the ordering is invariant.
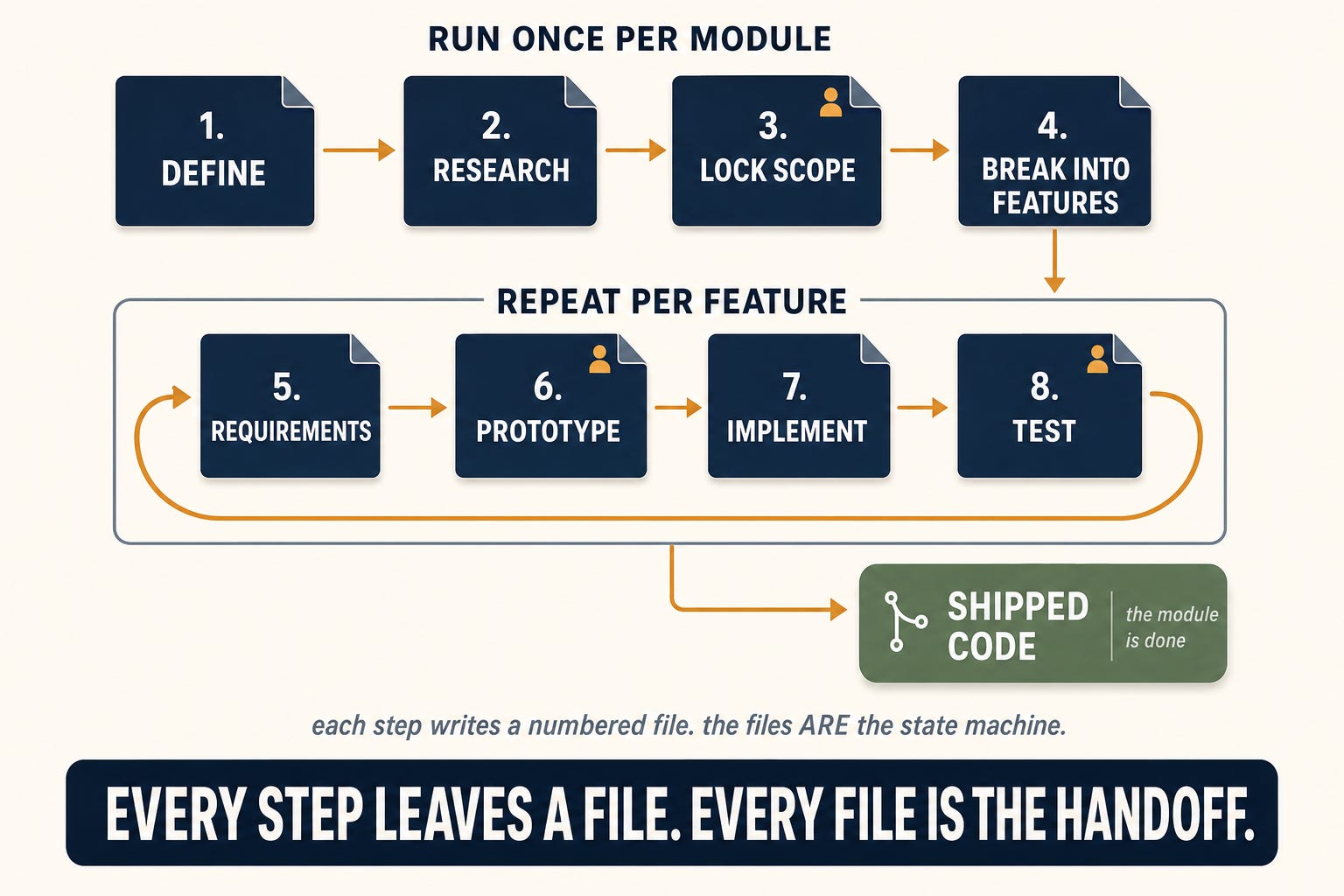
Module-level, run once:
Define the module. A short charter: what it is, who uses it, what the legacy system already does here, what a rebuild has to respect.
Research the landscape. Deep competitive and industry research against that charter. The AI becomes an expert in the problem, not a code generator pointed at the repo.
Lock the scope. Turn the research into a frozen scope every feature inherits. First human gate: the freeze. A developer and a domain expert confirm what’s in, and what’s out.
Break it into features. Split the scope into features in dependency order, so each feature’s inputs already exist when you reach it.
Per feature, looped until the module is done:
Lock the feature’s requirements. A working session that freezes this slice’s requirements.
Prototype it. A multi-agent pipeline produces a clickable, polish-gated UI in 1-2 hours. The prototype is the production UI: same React app, same design system, only the backend mocked. (Its own deep-dive: Most “AI in a day” ships slop. This pipeline has to clear the bar first) Second human gate: the prototype review. Someone opens it in a browser and uses it. This is a product review, not a code review.
Implement it. An orchestrator dispatches specialist subagents through plan-sized steps, runs review gates between them, and commits when they pass.
Test it. Scenarios automatically generated from the frozen requirements get tested against the real app. Automated testing takes care of 95% of test scenarios, and flags the 5% that need a human to run by hand. Third human gate: the ship decision. A human uses the module and decides whether it’s ready for production.
The full command sequence that runs a module through every one of these steps, start to finish, is its own post: How I run an entire module rebuild, start to finish.
Three things hold this together. The AI recommends, but a human always makes the final call: the AI does the reading, the human owns the decision. The work is broken into small pieces, because the AI does careful work on a small, well-defined task and sloppy work on a big vague one. And every step is written down as it finishes, so the work can always be picked up later exactly where it stopped.
AI for the parts where AI is good, humans for the parts where humans are good, and gates between them that neither side can skip.
What this is worth: the actual time savings
This isn’t a “10x productivity” story. Brownfield rewrites that used to be 18-month death marches now run as a sequence of 1-2 week phases with clear gates. The AI does most of the typing, reading, and scaffolding, but not the team’s judgment about what to build.
And the time savings aren’t the whole story. The output is better:
It’s an actually-clickable prototype, not a static mock. The team reacts to a running thing.
The requirements are sharper, and some are ideas the team wouldn’t have produced on its own. Not because the AI is smarter, but because it reads at a breadth no human has time for. It studies how dozens of other products solve the same problem, including ones in neighboring markets the team would never think to look at, and surfaces patterns we hadn’t considered.
It catches requirements gaps that would have shipped. A working prototype surfaces the “wait, that’s not what we meant” moments that a spec document hides. That alone has saved us from multiple multi-week reworks.
That’s the trade: less time, better output, and a working artifact to validate it. Everything downstream of the prototype (the freeze, the plan gates, the orchestrated implementation) exists to hold that gain across an entire rewrite, not just a single feature.
What I’d tell a team starting this work
If you’re staring at a legacy system wondering whether AI can help with the rewrite, the answer is yes, but the approach matters more than the tools. What I’d put on the wall before you start:
Break your application into large modules, and rebuild one at a time. The module is the unit of work, of risk, and of cutover.
Make competitor and adjacent-industry research a real step, not a footnote.
Put at least a developer and a product manager in the room for requirements. Some of the decisions are business decisions, and they need someone who owns the business there to make them.
Build the prototype before you commit to the implementation, and freeze requirements after it, not before. The prototype is the cheapest place to be wrong, and the contract everything downstream builds against.
The brownfield rewrite is the hardest thing software does. AI doesn’t make it easy. It makes it possible at a different speed and cost, but only if you build the scaffolding that respects how hard the problem actually is.
I’m Adam Miles. 25 years of shipping software, including the messy brownfield kind. I write about using AI to move real codebases forward: legacy, greenfield, and the awkward middle.
If you’re rebuilding a legacy system, or thinking about it, I’m happy to compare notes. I’m doing this work right now, the lessons are fresh, and I learn as much from the conversations as I share.
The companion to this post:
How I run an entire module rebuild, start to finish: this same spine written out as the exact command sequence that takes one module from empty folder to shipped. If this post is the why, that one is the how.
Deeper dives on two of the steps:
Most “AI in a day” ships slop. This pipeline has to clear the bar first: the multi-agent pipeline that compresses feature design from weeks to hours.
Subagents solve one AI problem. Orchestration hides another: the engineering discipline that keeps long-running AI work in the sharp zone.