
Subagents solve one AI problem. Orchestration hides another.
If you're chaining AI agents to do real work, your context discipline lives or dies on what you can't see. Here's the three-rule discipline I run on a production codebase every day.

You already know AI quality degrades as context fills. Past about 40% you start to feel it; past 70% you’re in the Dumb Zone. (Working heuristic, not a constant. The readable write-ups: [Justin Smith](The 40% Rule: Beating Claude’s ‘Dumb Zone’ on Large Codebases), [Dale Husband](Escaping the Dumbzone, Part 1: Why Your AI Gets Stupider the More You Talk to It).) The single-session toolkit is well-covered: `/clear`, `/compact`, scoped file reads, deliberate session resets, and spawning subagents to do research for you. Use them. They work.
This post isn’t about any of that. It’s about what happens when you take the next step and let an orchestrator drive multiple AI agents on your behalf, each with its own context window you can’t see.
The orchestration problem
An orchestrator is a foreman. It doesn’t lay bricks or wire outlets. It reads the blueprint, calls the right specialist in, inspects what they handed back, calls the next specialist, and keeps the job moving until the building stands. No specialist sees the whole job; only the foreman does.
A good foreman also doesn’t run their crew into the ground. Tired bricklayers make mistakes, so the foreman rotates them out before that happens. The orchestrator does the same: dispatch isn’t just about who’s doing the work, it’s about who’s still sharp enough to do it well.
The state-machine layer (inspect handoff, decide next step, dispatch) is what makes orchestration different from a bash script that runs commands in a fixed order.
The invisible failure mode
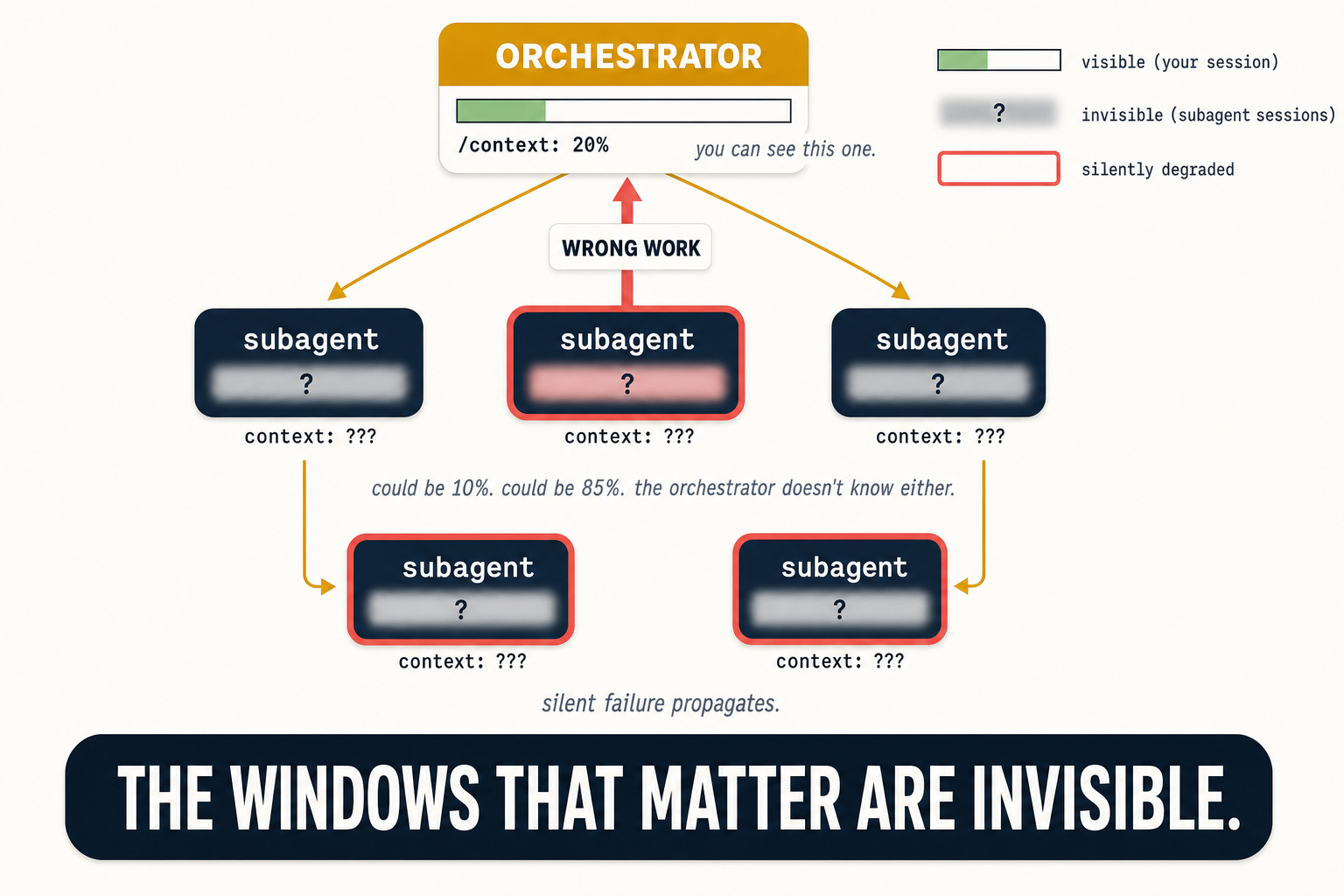
Subagents solved the visible problem. Orchestration brings it back invisible. When you spawn a subagent manually, you’re still in the loop: you see the digest, you decide whether to spawn another, you catch what looks off. When an orchestrator spawns subagents on your behalf, the context windows that matter are no longer ones you can see. No dashboard tells you agent #3 came back from a 65%-full session and agent #5 came back from an 18%-full session. Each long-running subagent degrades as it fills, and you weren’t the one who decided to spawn it.
A worker at 70% context misreads a column type, returns a migration that looks right at a glance, and the orchestrator builds an API endpoint on top of it. A long session crashes loud. An orchestration produces bad work quietly, the whole time.
The good news: it’s a structural problem with a structural solution. The piece that makes it work is handoff files. A handoff file is a short, structured note an agent writes before its session ends. The next agent reads the note and picks up from a 0% context window. The state lives on disk, not in any session’s memory.
With that piece in place, the rest follows. Three rules keep every session in the tree under the 40% line: one for the orchestrator, one for the subagents it dispatches, one for the long-running workers that save their state to disk.
Rule 1: The orchestrator never does the work itself
The hardest session to keep sharp is the orchestrator’s own. A wrong call by an orchestrator at 50% context isn’t one mistake. It’s a dozen subagents working on the wrong thing.
The mechanism that keeps the orchestrator’s context low is simple: it doesn’t do the work. No source file reads. No tool output dumps in its own session. No long-form analysis. The orchestrator’s only job is to dispatch: spawn the right subagent, inspect the handoff that comes back, decide what’s next, spawn again. Every byte of “real work” that lives in the orchestrator’s session is a byte that didn’t need to be there.
Rule 2: Delegate discovery to read-only locators
The orchestrator stays light by not reading source files. But knowing which source files matter, and what’s in them, is still required to make good decisions. That’s discovery: read-only research about the codebase, the database, the conventions. Someone has to do it.
The answer is a specialized subagent (a locator) that the orchestrator delegates the discovery to. Treat every file read as a context withdrawal. Spawning a subagent is almost nothing; pulling five files into the parent’s context window stays there for the rest of the session.
A subagent that reads 2,000 lines of source and returns 80 words of summary is the trade you want, every time.
One general-purpose search agent isn’t enough. Every distinct research domain in your project deserves its own locator. I run two currently:
`code-finder`: filesystem locator. “Where is X defined?” “What touches Y?” Returns file:line maps with ≤10-line excerpts. Never dumps whole files.
`db-finder`: database locator. Read-only DB access via MCP tools. Returns table:column digests instead of raw `describe_table` JSON, plus flags for project-specific conventions a general agent wouldn’t know.
You don’t need an orchestrator to want these. The locators pay off in any manual session too. Next time you’d point Claude at half a dozen files to answer “where does this get called from,” let it route to a `code-finder` instead and hand back a tight file:line map while your own context stays clean. The discovery happened; the source it waded through never entered your window. They’re the cheapest, highest-leverage thing in this whole post to steal, in an orchestrator or out of one.
For cross-layer questions (”where does this stored proc get called from the API?”), both locators get spawned in parallel from the same turn. One turn, two agents, two digests. The orchestrator never reads a file.
I don’t type anything different to use these. Claude reads the CLAUDE.md rules (”DB questions go to db-finder, code questions go to code-finder, cross-layer questions go to both in parallel”) and routes the request automatically. Write the rule once; get correct routing forever.
Each locator is 40-60 lines of plain English plus an output template, and pays for itself the third time you use it.
Rule 3: Long-running agents save state to disk and hand themselves off
Workers (implementers, reviewers, anything multi-step) take many turns and do real writes. No session can hold that safely across the budget, so the state goes where it already belongs: on disk.
When a worker finishes its assigned task, it writes a `handoff.md` describing what it did, then ends. The orchestrator reads the handoff to decide what comes next. If more work remains, a fresh worker reads the same handoff and continues. The orchestrator never holds the worker’s session context; the worker never carries forward across sessions.
A good handoff says four things:
What was produced. “Wrote three migrations and one stored proc.”
Completed steps. What not to redo.
Remaining steps. In execution order.
Recovery notes. Gotchas, partial work in flight, decisions made along the way.
A real one:
Produced: Migration `2024-05-17-add-couples-flag.sql`, stored proc `sp_Booking_GetCouples`, updated `BookingController.cs`, integration tests for the new endpoint.
Completed: Steps 1–4 of phase 02-backend-implementation. Tests written and passing.
Remaining: Step 5 (add the audit-log row on couples-flag change), step 6 (wire the new proc into the existing `BookingService` retry path).
Recovery notes: The proc returns `’True’`/`’False’` BOOLSTR, not `bit`. Any caller has to coerce. The `BookingController` already does; `BookingService` retry path does not yet.
Every worker writes one in the same shape, every time, so any future agent can parse it without guessing. Refusal cases are first-class citizens too: when a worker can’t do the work (wrong tool, oversized request, blocked by missing inputs) it still writes a handoff saying why and what needs to change.
Even if you never build a full orchestrator, the handoff pattern is stealable today. At the end of any meaningful session, ask Claude to write one for “the next you,” save it in the repo, and open the next session by reading it. You’ll feel the difference immediately.
Task completion isn’t the only handoff trigger. A worker that gets handed 30 sub-steps will start in the Safe Zone and end deep in the Dumb Zone if it tries to run them all in one session. So the agents themselves know about the budget. My implementer agents self-monitor their step and turn count. After a set threshold, they finish the step they’re on, write a handoff, and return. The orchestrator catches the early return and spawns a fresh implementer with clean context to continue. Nothing in the system is allowed to outlive its budget.
The same discipline keeps the orchestrator out of trouble. If you’ve applied the three rules (it dispatches instead of working, discovery goes to locators, long tasks hand themselves off), the orchestrator’s own context stays lean almost by construction. So if you ever watch an orchestrator climb past 40%, don’t reach for a bigger budget. Take a step back and find what’s bloating it: it’s reading files it should be delegating, or holding work that belonged in a subagent. A well-run orchestrator should rarely get near the line. One caveat: an orchestrator can’t safely resume itself (a Claude-harness limitation I ran into), so mine don’t try. When one crosses the threshold, it saves its state and stops, printing the command to resume. I re-run it in a fresh session and it picks up where it left off. A one-line handoff instead of a silent failure. If you want the details of why self-resume breaks, message me.
There’s a second benefit most people miss: each forced handoff is an implicit review checkpoint. When work is split into bounded sessions, the orchestrator inspects each handoff before spawning the next agent. It’s AI reviewing AI’s output, with fresh context, at a deliberate stopping point. Drift gets caught at the first step, while it’s still small and cheap to fix.

The orchestration discipline, in one screen
The orchestrator dispatches; it never does the work itself. No source reads, no tool output in its own session.
Discovery goes to read-only locators. Digest output, word-capped, gotcha-surfacing. One locator per domain.
Long-running subagents hand themselves off. Structured handoff files on disk, self-triggered when budget pressure hits. Workers and orchestrators both stop while still sharp. A worker’s parent respawns it; the orchestrator has no parent to do that, so it can only resume as a fresh top-level session.
The promise this delivers: larger multi-step work runs cleanly across many fresh sessions, with no single session falling into the degraded zone. Work where the combination of steps is the size, not any single step, becomes work the orchestrator handles one fresh session at a time.
None of this is magic. All of it is boring discipline applied to the one resource everyone underestimates the moment they start chaining agents.
Subagents are the visible fix. The discipline in this post is the invisible one.
---
I’m Adam Miles. 25 years of shipping software, including the messy brownfield kind. I write about using AI to move real codebases forward: legacy, greenfield, and the awkward middle.
If you’re building AI orchestration for real codebases and running into context discipline problems, I’m happy to compare notes. I’m doing this work right now, the lessons are fresh, and I learn as much from the conversations as I share.